数理統計II
担当: 菊地
第4回 確率変数
2006.4.27
4.1 確率変数と確率分布
- 確率変数
-
変数がとる各値に対して確率が与えられているような変数を確率変数と呼ぶ。Xのように大文字を用いる。例えば、サイコロを振って出た目をXとすると、Xは確率変数として定義できる。その確率は、
-
P(X=1)=1/6, P(X=2)=1/6, ..., P(X=6)=1/6
となる。さらに、2個のサイコロX1、X2の目の和Y=X1+X2も確率変数として定義できる。
- 離散型の確率変数
-
一般に、離散的な値{x1, x2, ...}の中の一つの値をとる確率変数Xを、離散型の確率変数と呼ぶ。
また、離散型の確率変数Xが、それぞれの値をとる確率
-
f(xk)=P(X=xk) (k=1, 2, ...)
をXの確率分布と呼ぶ。
このfは、
-
f(xk)>=0 かつ Σf(xk) = 1
の条件を満たす。このようなfを離散型の確率分布と呼ぶ。f(xk)は、単にf(x)と書かれることが多い。
- 連続型の確率変数
-
一般に、連続的な値をとる確率変数のことを連続型の確率変数と呼ぶ。確率変数Xがある範囲の値をとる確率が関数f(x)によって、
-
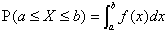
のように表される場合、Xは連続型の確率変数である。ただし、このf(x)は離散型の場合と同様に、
-
f(x)>=0 かつ
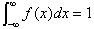
を満たす。この連続型の確率分布を表すf(x)を確率密度関数あるいは単に密度関数と呼ぶ。
- 累積分布関数
-
確率変数Xに対して、xを実数とする時、Xがx以下となる確率を表す関数
-
F(x) = P(X<=x)
をXの累積分布関数と呼ぶ。
連続型の場合には、区間(-∞, x]に関してf(x)を積分した値になる。逆に、確率密度関数は累積分布関数の導関数である。F(x)、f(x)のどちらでも確率分布を表すことができる。
離散型の場合には、確率を-∞からxまで積み上げて和をとったものになる。
- 累積分布関数の性質
-
- a) 広義の単調増加
-
x1 < x2 ならば、F(x1) <= F(x2)
- b) 範囲
-
x→∞の時、F(x)→1
x→-∞の時、F(x)→0
- c) 右連続
-
ε>0とし、各点xでε→0の時、F(x+ε)→F(x)
- モードとメディアン
-
モードは分布の山の頂点であり、f(x)が最大になる点である。また、メディアンは、F(x)=1/2となる点である。
4.2 確率変数の期待値と分散
- 期待値
-
一般に確率変数Xの期待値E(X)は、
- 離散型の場合、
-
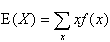
- 連続型の場合、
-
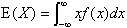
で定義される。
確率変数Xの期待値E(X)は、いわゆる平均値であり、確率変数のとる値をその確率で重みをつけて、平均をとったものである。
- 期待値の性質
-
X、Yを確率変数、cを定数とすると、
(a) E(c) = c
(b) E(X+c) = E(X) + c
(c) E(cX) = cE(X)
(d) E(X + Y) = E(X) + E(Y)
を満たす。
- 分散
-
第2回の講義で、分布の幅、散らばりを定義するための尺度として分散を紹介したが、その定義は、データの値と平均値の差の2乗の平均であった。確率変数の分散は、期待値を利用して、以下のように定義できる。Xの期待値(平均)をμ=E(X)、Xの分散をV(X)とすると、
-
V(X) = E((X - μ)2) = E(X2) - μ2
となる。
- 分散の性質
-
(a) V(c) = 0
(b) V(X+c) = V(X)
(c) V(cX) = c2V(X)
- 標準偏差
-
Xの標準偏差D(X)は、V(X)の平方根D(X) = √V(X)で計算される。なお、分散の値をσ2、標準偏差の値をσで表すことが多い。
- 標準化
-
確率変数を変数変換し、Xの期待値を0、分散を1に調整することを標準化と呼ぶ。この変数変換は、
-
Z=(X - E(X)) / D(X)
であり、Zを標準化変数と呼ぶ。このように、期待値と分散をそろえることで、とる値の範囲が異なった、確率変数間の比較を行うことができる。
4.3 歪度(わいど)と尖度(せんど)
- 歪度(わいど)
-
分布の左右の非対称性を表す指標であり、
-
α3 = E((X-μ)3) / σ3
で定義される。α3 > 0 ならば、右の裾が長く、α3 < 0ならば、左の裾が長いことを表す。歪度係数とも呼ばれる。
- 尖度(せんど)
-
分布の尖りの程度を表す指標である。4乗の期待値
-
α4 = E((X-μ)4) / σ4
を計算し、正規分布で計算したα4(=3)と比較する。通常は、α4 - 3を確率変数Xの尖度と呼び、α4 - 3 > 0ならば正規分布より尖っており、α4 - 3 < 0ならば正規分布より丸い形をしている。超過係数とも呼ばれる。
4.4 チェビシェフの不等式
どのような確率変数Xであっても期待値(平均)のそばの値に確率が集中していることを表す不等式である。
確率変数Xに対して、期待値をμ、標準偏差をσとすると、
-
P(|X - μ| >= kσ) <= 1/k2
が成り立つ。これをチェビシェフの不等式という。
これは、いかなる確率変数についても成り立つという意味で絶対的なものであり、平均と分散がわかっていれば、f(x)が具体的にわかっていなくても計算ができる点がメリットである。例えば、k=2の場合を考えると、確率変数Xの値が、期待値よりも±2σ以上離れた値となる確率は、1/4以下である。同様に、k=3の場合には、1/9以下である。このように考えると、期待値から離れれば離れるほど、その確率が少なくなることがわかる。