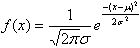
で定義され、ガウス分布とも呼ばれる。平均μ、分散σ2に従う正規分布を、N(μ,σ2)で表す。
測定誤差は、正規分布に従うとされるので、測定を行う場合には正規分布が関係してくる。また、生物測定の分野ではあてはまる場合が多い。
正規分布の特徴は以下のようなものである。
-
a) XがN(μ,σ2)に従っている時、その線形変換Y=aX+bはN(aμ+b,a2σ2)に従う。
b) 標準化変数Z=(X-μ)/σは正規分布N(0,1)に従う。これを標準正規分布と呼ぶ。
このことから、いかなる正規分布の確率計算も、標準正規分布を用いたものに帰着できる。
標準正規分布の累積分布関数は、正規分布表として多くの教科書にのっているが、主な区間の確率がよく知られている。
-
P(-1 <= Z <= 1) = 0.6827 (ほぼ2/3)
P(-2 <= Z <= 2) = 0.9545 (ほぼ95%)
P(-3 <= Z <= 3) = 0.9973 (ほぼ100%)
なお、-3<=Z<=3は、もとのXでいえば-3σ<=X<=3σに相当し、常識的に考えるとすべての観測値がこの範囲に入る。このことから、「事実上のすべて」という意味で3シグマ範囲と呼ばれることがある。
入試などで用いられる偏差値は、得点を平均が50、標準偏差が10(分散が100)になるように標準化したものである。得点分布が正規分布に従うとすると、偏差値が40〜60の範囲(平均±1×標準偏差)に2/3の受験者が入り、30〜70の範囲(平均±2×標準偏差)に95%の受験者が入ることになる。
また、同一の確率分布f(x)を持つn個の独立な確率変数の和X1+X2+...+Xnは、nが大きくなると、もとの分布が何であろうと正規分布に近付く。データから計算された算術平均(標本平均)は、同一の確率変数の和をnで割ったものなので、正規分布をすると見なせる。これは中心極限定理によって示されている。
そして、正規分布には、再生性という有用な性質がある。独立な確率変数X, Yが正規分布N(μX, σX2), N(μY, σY2)に従うとき、aX + bYは正規分布N(a μX + b μY, a2 σX2 + b2 σY2)に従う。